1 Машинное обучение: от Ирисов до Телекома

1.1 Анонс
У мобильных операторов связи очень много разнообразных данных. Я занимаюсь системой обслуживания трафика абонентов / https://www.billing.ru/products/orchestration/pcrf /, которая генерирует сотни Гигабайт статистической информации в сутки. И мне не давал покоя вопрос, а может в этих Больших Данных есть что-нибудь полезное? Не зря ведь одна из V в определении Big Data - это дополнительный доход. Но я не являюсь специалистом в исследовании данных, статистику смутно помню из университета и профессионально программировал только на С++. Сразу возникло масса вопросов - какие средства использовать для анализа? На каком уровне нужно знать математику, статистику? Какие методы машинного обучения надо знать и насколько глубоко? А может для начала лучше освоить специализированный язык для исследования данных R или Python?
Как показал мой опыт, для начального уровня исследования данных нужно совсем не много. Но во время изучения мне не хватало простого примера, на котором наглядно был бы показан полный алгоритм исследования данных. В статье на примере Ирисов Фишера / https://ru.wikipedia.org/wiki/Ирисы_Фишера / мы пройдем весь путь, а далее применим полученное понимание к реальным данным оператора связи. Люди знакомые с исследованием данных могут сразу переходить к Телекому.
Cut
Термины
Для начала давайте разберемся с тем, что будем изучать. Сейчас термины Искусственный Интеллект, Машинное Обучение, Глубокое Машинное Обучение зачастую используются, как синонимы, но на самом деле существует вполне определенная иерархия:
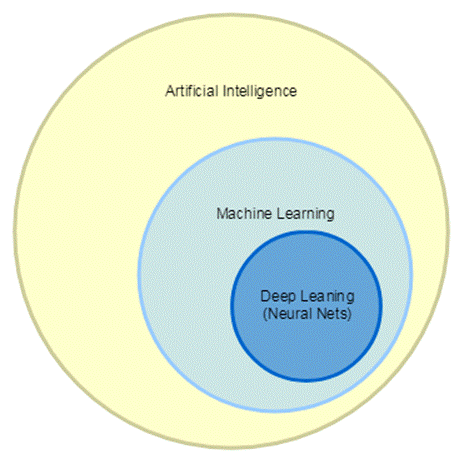
· К Искусственному Интеллекту относятся все задачи, в которых машины выполняют интеллектуальные задачи – игра в шашки или шахматы, помощники, способные распознавать речь и давать ответы на вопросы, разнообразные роботы.
· Машинное Обучение – более узкое понятие и относится к классу задач, для решения которых компьютер обучают выполнять определенные задачи, имея заранее известные правильные ответы, например, классификация объектов по набору признаков или рекомендация музыки и фильмов.
· Под глубоким обучением подразумевают задачи, которые решаются с помощью нейронных сетей и Больших Данных, такие как распознавание образов или перевод текста.
В статье мы будем говорить о Машинном Обучении. В нем выделяют два способа обучения:
· C учителем
· Без учителя
С учителем – это когда у нас есть данные с правильными ответами. Тогда алгоритм можно обучить на этом наборе данных, а далее применять их для предсказания. К таким алгоритмам относится классификация и регрессия. Классификация - это отнесение объектов к определенному классу по набору признаков. Например, распознавание номеров машин или в медицине диагностика заболеваний или кредитный скоринг в банковской сфере. Регрессия – это предсказание вещественной переменной, например цен на акции.
Без учителя или самообучение – это поиск скрытых закономерностей в данных. К таким алгоритмам относится кластеризация. Например, все крупные торговые сети ищут закономерности в покупках своих клиентов и пытаются работать с целевыми группами покупателей, а не с общей массой.
Есть еще несколько задач машинного обучения:
· Исследование графов - используется для анализа соц сетей, например для поиска людей, оказывающих наибольшее влияние на других;
· Геоаналитика - исследование перемещений людей, например, для того чтобы определить место открытия магазина или разместить рекламу
· Нейронные сети – используются как универсальный механизм для задач регрессии и классификации.
Основные инструменты исследования данных - регрессия, классификация и кластеризация, поэтому их и будем рассматривать.
1.2 Исследование данных
Алгоритм исследования данных состоит из определенной последовательности шагов. В зависимости от имеющихся данных и задачи набор шагов может меняться, но общее направление всегда определенное:
· Сбор и очистка данных. Как показывает практика, этот этап может занимать до 90% времени всего анализа данных;
· Далее смотрим на сами данные, их распределения, статистики;
· Смотрим на зависимость (корреляцию) между переменными (признаками);
· Отбираем и создаем признаки, которые будут использоваться для построения моделей;
· Разделяем данные на данные для обучения модели и тестовые;
· Цикл построения моделей на данных для обучения / оценка результата на тестовых данных;
· Интерпретация полученной модели, визуализация результатов.
С алгоритмом разобрались, а какие средства использовать для анализа? Существует масса средств, от Excel до специализированных средств, например, MathLab. Мы возьмем Python cо специализированными библиотеками. Не надо пугаться - тут все просто:
· Скачиваем Python и все математические пакеты в одном дистрибутиве, который называется Анаконда: https://www.continuum.io/downloads
· Установка и запуск под Linux проблем не вызывает:
bash Anaconda2-4.4.0-Linux-x86_64.sh
· Запускаем:
jupyter notebook
· При этом автоматически открывается браузер
· Проверяем, что все работает:
print "HelloWorld!"
· Нажимаем Ctrl-Enter, смотрим, что все ok:
Для самостоятельного изучения в интернете есть масса информации по работе в IPython Notebook, например простое введение: Обзор IPython Notebook 2.0: https://habrahabr.ru/post/218869/
А мы начинаем наше исследование!
1.2.1 Сбор и очистка данных
С Ирисами для нас все собрали и заполнили. Просто загружаем их и смотрим.
#Импортируем нужные библиотеки:
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import linear_model
from sklearn.cluster import KMeans
from sklearn import cross_validation
from sklearn import metrics
from pandas import DataFrame
%pylab inline
Далее:
# Загружаем набор данных Ирисы:
iris = datasets.load_iris()
# Смотрим на названия переменных
print iris.feature_names
# Смотрим на данные, выводим 10 первых строк:
print iris.data[:10]
# Смотрим на целевую переменную:
print iris.target_names
print iris.target

Видим, что набор данных состоит из длины / ширины двух типов лепестков Ириса: sepal и petal. Не спрашивайте меня, где они находятся у Ириса). Целевая переменная - это сорт Ириса: 0 - Setosa, 1 - Versicolor, 3 - Virginica. Соответственно, нашими задачами будут - по имеющимся данным попробовать найти зависимости между размерами лепестков и сортами Ирисов.
Для удобства манипулирования данными делаем из них DataFrame:
iris_frame = DataFrame(iris.data)
# Делаем имена колонок такие же, как имена переменных:
iris_frame.columns = iris.feature_names
# Добавляем столбец с целевой переменной:
iris_frame['target'] = iris.target
# Для наглядности добавляем столбец с сортами:
iris_frame['name'] = iris_frame.target.apply(lambda x : iris.target_names[x])
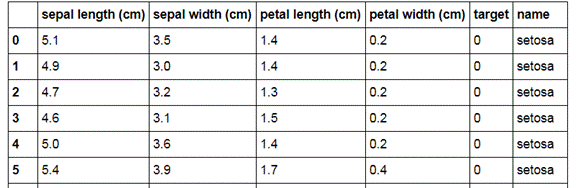
# Смотрим, что получилось:
iris_frame
Вроде получилось, то что хотели:
1.2.2 Описательные статистики
# Строим гистограммы по каждому признаку:
pyplot.figure(figsize(20, 24))
plot_number = 0
for feature_name in iris['feature_names']:
for target_name in iris['target_names']:
plot_number += 1
pyplot.subplot(4, 3, plot_number)
pyplot.hist(iris_frame[iris_frame.name ==
target_name][feature_name])
pyplot.title(target_name)
pyplot.xlabel('cm')
pyplot.ylabel(feature_name[:-4])
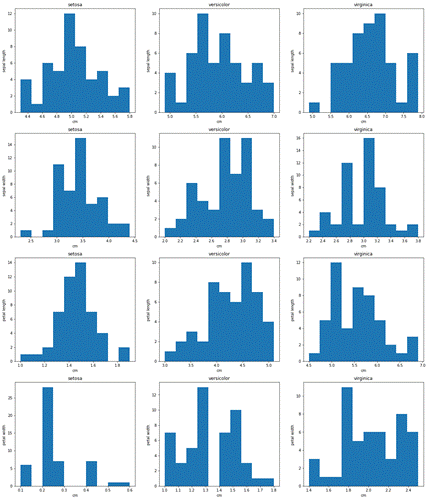
Посмотрев на такие гистограммы, опытный исследователь может сразу делать первые выводы. Я вижу только, что распределение у некоторых переменных похоже на нормальные, у некоторых имеет другой вид ). Далее делаем более наглядно. Строим таблицу с зависимостями между признаками и раскрашиваем точки в зависимости от сортов Ирисов:
import seaborn as sns
sns.pairplot(iris_frame[['sepal length (cm)','sepal width (cm)','petal
length (cm)','petal width (cm)','name']], hue = 'name')
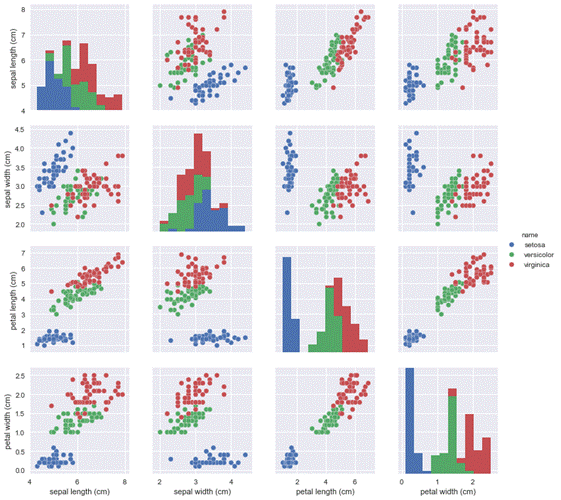
Тут уже даже мне видно, что "petal width (cm)" и "petal length (cm)" имеют сильную зависимость - точки вытянуты вдоль одной линии. И в принципе по этим же признакам можно строить классификацию, т.к. точки по цвету сгруппированы достаточно компактно. А вот, например, с помощью переменных "sepal width (cm)" и "sepal length (cm)" качественную классификацию не построить, т.к. точки относящиеся к сортам Versicolor и Virginica перемешаны между собой.
1.2.3 Зависимость между переменными
Теперь смотрим на математические значения зависимостей:
iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']].corr()
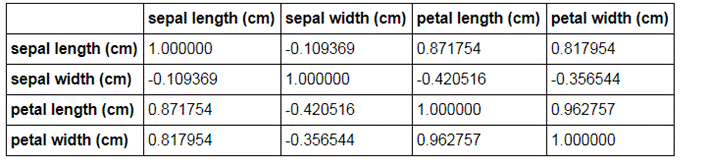
В более наглядном виде - строим тепловую карту зависимости признаков:
import seaborn as sns
corr = iris_frame[['sepal length (cm)','sepal width (cm)','petal length
(cm)','petal width (cm)']].corr()
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask)] = True
with sns.axes_style("white"):
ax = sns.heatmap(corr, mask=mask, square=True, cbar=False, annot=True,
linewidths=.5)
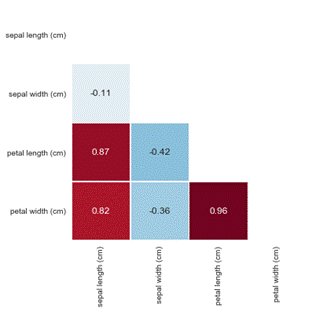
Значения коэффициента корреляции интерпретируются следующим образом:
· До 0,2 - очень слабая корреляция
· До 0,5 - слабая
· До 0,7 - средняя
· До 0,9 - высокая
· Больше 0,9 - очень высокая
Действительно видим, что между переменными "petal length (cm)" и "petal width (cm)" выявлена очень сильная зависимость 0.96.
1.2.4 Отбираем и создаем признаки этап N1
В первом приближении можно просто включить все переменные в модель и посмотреть что будет. Далее можно подумать, какие признаки убрать, а какие создать.
1.2.5 Данные для обучения и тестовые данные
Разделяем данные на данные для обучения и тестовые данные. Обычно выборку разделяют на обучающую и тестовую в процентном соотношении 66/33 или 70/30 или 80/20. Возможны и другие разбиения в зависимости от данных. В нашем примере на тестовые данные отводим 30% от всей выборки (параметр test_size = 0.3):
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3, random_state = 0)
# смотрим что все правильно:
print train_data
print test_data
print train_labels
print test_labels
1.2.6 Цикл построения моделей – оценка результата
Переходим к самому интересному.
1.2.6.1 Линейная регрессия – LinearRegression
Как наглядно представить линейную регрессию? Если смотреть на зависимость между двумя переменными – то это проведение линии, так чтобы расстояния от линии до точек были в сумме минимальные. Самый распространенный способ оптимизации – это минимизация среднеквадратичной ошибки по алгоритму градиентного спуска. Объяснение градиентного спуска есть много где, например тут ( https://habrahabr.ru/post/313216/ ) в разделе “Что такое градиентный спуск?”. Но можно не читать и воспринимать линейную регрессию, как абстрактный алгоритм нахождения линии, которая наиболее точно повторяет направление распределения объектов. Строим модель, используя переменные, которые, как мы поняли ранее, имеют сильную зависимость - это "petal length (cm)" и "petal width (cm)":
from scipy import polyval, stats
fit_output = stats.linregress(iris_frame[['petal length (cm)','petal
width (cm)']])
slope, intercept, r_value, p_value, slope_std_error = fit_output
print(slope, intercept, r_value, p_value, slope_std_error)
Смотрим на метрики качества модели:
(0.41641913228540123, -0.3665140452167277, 0.96275709705096657, 5.7766609884916033e-86, 0.009612539319328553)
Из наиболее интересного - это r_value со значением 0.96275709705096657. Это коэффициент корреляции между переменными. Его мы уже видели ранее, а здесь еще раз убедились в его существовании. Рисуем график с точками и линией регрессии:
import matplotlib.pyplot as plt
plt.plot(iris_frame[['petal length (cm)']], iris_frame[['petal width (cm)']],'o', label='Data')
plt.plot(iris_frame[['petal length (cm)']], intercept + slope*iris_frame[['petal length (cm)']], 'r', linewidth=3, label='Linear regression line')
plt.ylabel('petal width (cm)')
plt.xlabel('petal length (cm)')
plt.legend()
plt.show()
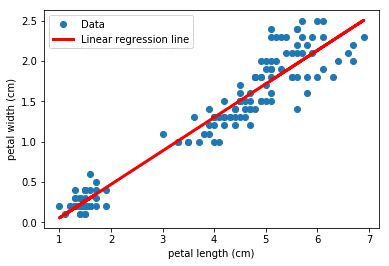
Видим, что, действительно, найденная линия регрессии хорошо повторяет направление распределения точек.
1.2.6.2 Классификация
Как интуитивно представить классификацию? Если смотреть на задачу разделения на два класса, объектов, которые имеют два признака (например нужно разделить яблоки и бананы, если известна их размеры), то классификация сводится к проведению линии на плоскости, которая делит объекты на два класса. Если надо разделить на большее число классов, то проводится несколько линий. Если смотреть на объекты с тремя переменными, то представляется трехмерное пространство и задача проведения плоскостей. Если переменных N, то нужно просто вообразить гиперплоскость в N мерном пространстве).
Итак берем самый известный алгоритм стохастического градиентного спуска (Stochastic Gradient Descent). С градиентным спуском мы уже встречались в линейной регрессии, а стохастический говорит о том, что для быстроты работы используется не вся выборка, а случайные данные.
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame[['target']], test_size = 0.3, random_state = 0)
model = linear_model.SGDClassifier(alpha=0.001, n_iter=100, random_state = 0)
model.fit(train_data, train_labels)
model_predictions = model.predict(test_data)
print metrics.accuracy_score(test_labels, model_predictions)
print metrics.classification_report(test_labels, model_predictions)
Смотрим на метрики качества модели:
accuracy: 0.933333333333
precision recall f1-score support
0 1.00 1.00 1.00 16
1 1.00 0.83 0.91 18
2 0.79 1.00 0.88 11
avg / total 0.95 0.93 0.93 45
На самом деле, оценить модель можно, не особо разбираясь в сути значений: если accuracy, precision и recall больше 0.85, то это хорошая модель, если больше 0.95, то отличная. Но для цельности повествования кратко расскажу про метрики:
· accuracy - это главная метрика, которая показывает долю правильных ответов модели. Ее значение равно отношению числа правильных ответов, которые дала модель, к числу всех объектов. Но она не полностью отражает качество модели. Поэтому вводятся precisionона и recall.
Эти метрики даны как в разрезе качества распознавания каждого класса, так и суммарные значения. Смотрим на суммарные значения:
· precision (точность) - эта метрика показывает, насколько мы можем доверять модели, другими словами, какое у нас количество "ложных срабатываний". Значение метрики равно отношению числа ответов, которые модель считает правильными и они действительно были правильными к сумме этого числа и числа объектов которые модель посчитала правильными, а на самом деле они были неправильные.
·
recall (полнота) - эта метрика показывает насколько
модель может вообще обнаруживать правильные ответы, другими словами, какое у
нас количество "ложных пропусков". Ее численное значение равно
отношению ответов, которые модель считает правильными и они действительно были
правильными к числу всех правильных ответов в выборке.
· f1-score (f-мера) - это объединение precision и recall
· support - просто число найденных объектов в классе
Есть еще важные метрики модели: PR-AUC и ROC-AUC, но сейчас не будем на них останавливаться.
Т.о. видим, что значения очень даже хорошие. Смотрим на картинку. Для наглядности выборку рисуем в двух координатах и раскрашиваем по классам. Сначала тестовую выборку, как она есть:
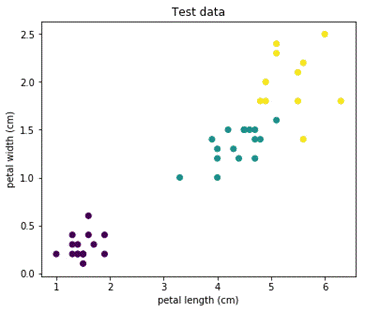
Потом, как ее предсказала наша модель. Видим, что точки на границе (обвел красным) были классифицированы не правильно:
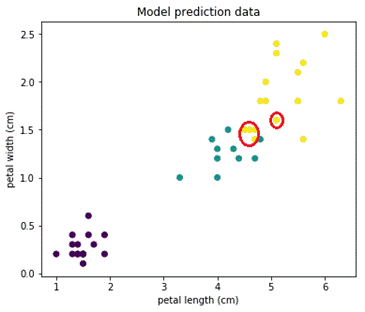
Но при этом большинство объектов предсказано правильно!
1.2.6.3 Cross-Validation
Как-то уж очень подозрительно хороший результат... Что может быть не так? Например мы случайно хорошо разбили данные на обучающую и тестовую выборку. Чтобы убрать эту случайность применяют так называемую кросс-валидацию. Это когда данные разбиваются несколько раз на обучающую и тестовую выборку и результат работы алгоритма усредняется. Проверим работу алгоритма на 10 выборках:
train_data, test_data, train_labels, test_labels =
cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width
(cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size
= 0.3)
model = linear_model.SGDClassifier(alpha=0.001, n_iter=100, random_state
= 0)
scores = cross_validation.cross_val_score(model, train_data,
train_labels, cv=10)
print scores.mean()
Смотрим на результат, он ожидаемо ухудшился:
0.860909090909
1.2.6.4 Подбор оптимальных параметров алгоритма
Что еще можно сделать для оптимизации алгоритма? Можно попытаться подобрать параметры самого алгоритма. Видим, что в алгоритм передаются alpha=0.001, n_iter=100. Давайте найдем для них оптимальные значения.
from sklearn import grid_search
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3)
parameters_grid = {
'n_iter' : range(5,100),
'alpha' : np.linspace(0.0001, 0.001, num = 10),
}
classifier = linear_model.SGDClassifier(random_state = 0)
cv = cross_validation.StratifiedShuffleSplit(train_labels, n_iter = 10, test_size = 0.3, random_state = 0)
grid_cv = grid_search.GridSearchCV(classifier, parameters_grid, scoring = 'accuracy', cv = cv)grid_cv.fit(train_data, train_labels)
print grid_cv.best_estimator_
На выходе получаем модель с оптимальными параметрами:
SGDClassifier(alpha=0.00089999999999999998,
average=False, class_weight=None,
epsilon=0.1, eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', n_iter=96, n_jobs=1,
penalty='l2', power_t=0.5, random_state=0, shuffle=True, verbose=0,
warm_start=False)
Видим, что в ней alpha=0.0009, n_iter=96. Подставляем эти значения в модель:
train_data, test_data, train_labels, test_labels =
cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width
(cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size
= 0.3)
model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state
= 0)
scores = cross_validation.cross_val_score(model, train_data,
train_labels, cv=10)
print scores.mean()
Смотрим, стало немного лучше:
0.915505050505
1.2.6.5 Отбираем и создаем признаки этап N2
Пришло время поэкспериментировать с признаками. Давайте уберем из модели менее значимые признаки, а именно "sepal length (cm)" и "sepal width (cm)". Загоняем в модель:
train_data, test_data, train_labels, test_labels =
cross_validation.train_test_split(iris_frame[['petal length (cm)','petal width
(cm)']], iris_frame['target'], test_size = 0.3)
model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state
= 0)
scores = cross_validation.cross_val_score(model, train_data, train_labels,
cv=10)
print scores.mean()
Смотрим, стало еще немного лучше:
0.937727272727
Для иллюстрация подхода, давайте сделаем новый признак: площадь листка petal и посмотрим что получится.
iris_frame['petal_area'] = 0.0
for k in range(0,150):
iris_frame['petal_area'][k] = iris_frame['petal length (cm)'][k] *
iris_frame['petal width (cm)'][k]
Подставляем в модель:
train_data, test_data, train_labels, test_labels =
cross_validation.train_test_split(iris_frame[['petal_area']],
iris_frame['target'], test_size = 0.3)
model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state = 0)
scores = cross_validation.cross_val_score(model, train_data, train_labels,
cv=10)
print scores.mean()
Смотрим, забавно но получается, что площадь лепестка petal (вернее, даже не площадь, т.к. лепестки не прямоугольники, а "произведение длины на ширину") наиболее точно предсказывает сорт Ириса:
0.942373737374
Наверно это можно объяснить тем, что переменные 'petal length (cm)' и 'petal width (cm)', и так неплохо разделяет Ирисы на классы, а их произведение как-бы еще растягивает классы вдоль прямой:
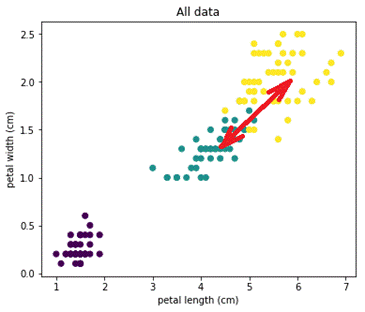
Мы познакомились с основными способами оптимизации моделей, теперь рассмотрим алгоритм кластеризации - пример машинного обучения без учителя.
1.2.6.6 Кластеризация - K-means
Суть кластеризации крайне проста - необходимо разделить имеющиеся объекты на группы, так чтобы в группы входили похожие объекты. У нас теперь нет правильных ответов для обучения модели, поэтому алгоритм должен сам группировать объекты по "близости" расположения объектов друг к другу. Для примера, рассмотрим самый известный алгоритм K-средних. Он не зря называется K-средних, т.к. метод основан на нахождении K центров кластеров так, чтобы среднее расстояния от них до объектов, которые им принадлежат были минимальные. Сначала алгоритм определяет K произвольных центров, далее все объекты распределяются по близости к этим центрам. Получили K кластеров объектов. Далее в этих кластерах заново вычисляются центры по среднему расстоянию до объектов и объекты снова перераспределяются. Алгоритм работает до тех пор пока центры кластеров не перестанут сдвигаться на какую-то определенную дельту.
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame[['target']], test_size = 0.3)
model = KMeans(n_clusters=3)
model.fit(train_data)
model_predictions = model.predict(test_data)
print metrics.accuracy_score(test_labels,
model_predictions)
print metrics.classification_report(test_labels, model_predictions)
Смотрим на результаты:
accuracy: 0.911111111111
precision recall f1-score support
0 1.00 1.00 1.00 20
1 0.73 1.00 0.85 11
2 1.00 0.71 0.83 14
avg / total 0.93 0.91 0.91 45
Видим, что даже с параметрами по умолчанию получается очень неплохо: accuracy, precision и recall больше 0.9. Убеждаемся на картинках, видим достойный, но не везде точный результат:
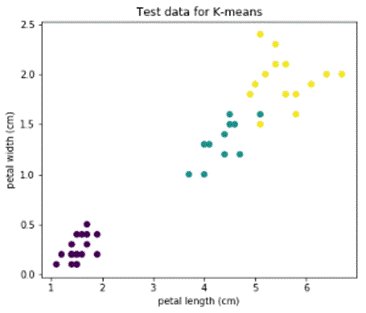
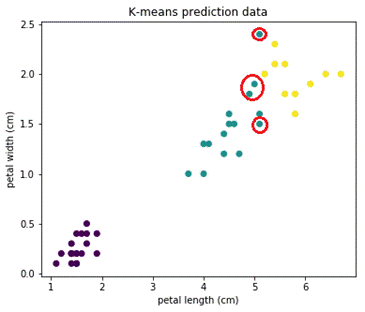
У алгоритма есть недостаток, что для его работы нужно задавать число кластеров, которое мы хотим найти. И если задать неадекватное число кластеров, то результаты работы алгоритма будут бесполезны. Посмотрим, что будет, если задать число кластеров, например, 5:
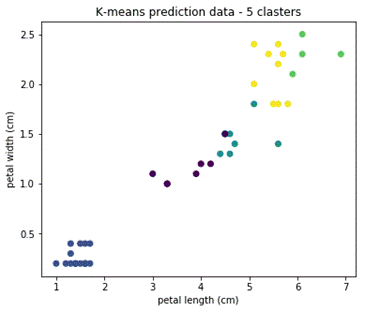
Видим, что результат не имеет никакого отношения к действительности. Существуют алгоритмы определения оптимального числа кластеров, но в этой статье мы не будем на них останавливаться.
1.2.7 Заключение по исследованию Ирисов
Итак, на примере Ирисов мы рассмотрели 3 основных метода машинного обучения: регрессию, классификацию и кластеризацию. Провели оптимизацию алгоритмов и визуализацию результатом. Получили очень хорошие результаты, но так и должно было быть на специально подготовленном наборе данных)
Весь Python Notebook лежит на Github: https://github.com/ASushkov/Iris
Переходим к Телекому!
1.3 Телеком
В Телекоме есть задачи, которые с помощью анализа данных решают и в других сферах (банки, страхование, ретейл):
· Предсказание оттока абонентов (Churn Prevention)
· Обнаружение мошенничества (Fraud Prevention)
· Выявление похожих абонентов (Сегментация абонентской базы)
· Перекрестные продажи (Cross-Sale) и поднятие суммы продажи (Up-Sale)
· Выявление абонентов, сильно влияющих на свое окружение (Альфа-абоненты)
Так и специфичные задачи:
· Предсказание потребления ресурсов сети абонентами: объём трафика, число звонков, SMS
· Исследование перемещений абонентов с целью оптимизации сети
Откуда берутся данные у оператора связи? Из разнообразных информационных систем и оборудования, которое участвует в предоставлении услуг абонентам:
· В биллинговой системе хранятся данные по платежам и расходам абонентов, тарифы, персональные данные;
· Из оборудования DPI / https://ru.wikipedia.org/wiki/Deep_packet_inspection / получаются данные о том, какие сайты посещал абонент;
· C базовых станций можно получить геоданные c местонахождением абонента;
· Оборудование обслуживания генерирует данные о потреблении абонентом услуг связи
Моим желанием было посмотреть, какие задачи можно попробовать решить с помощью данных, которые генерирует наша система по обслуживанию трафика абонентов. Информация о потреблении трафика сохраняется в виде CDR (Call Data Record) файлов. В эти файлы в csv формате записываются идентификаторы абонента (IMSI, MSISND), местоположение c точностью до базовой станции, идентификатор оборудования абонента (IMEI), временная метка сессии и информация о потребленной услуге. К сожалению, у меня нет доступа к объему и типу абонентского трафика, т.к. эта информация получается из DPI. Поэтому эти данные я cгенерировал в соответствии со своим пониманием. Также для соблюдения конфиденциальности следующие параметры сгенерированны случайным образом с соблюдением формата: IMSI ( https://ru.wikipedia.org/wiki/IMSI ), MSISDN (https://ru.wikipedia.org/wiki/MSISDN), IMEI ( https://ru.wikipedia.org/wiki/IMEI ) и CELL_ID. Посмотрим на данные:
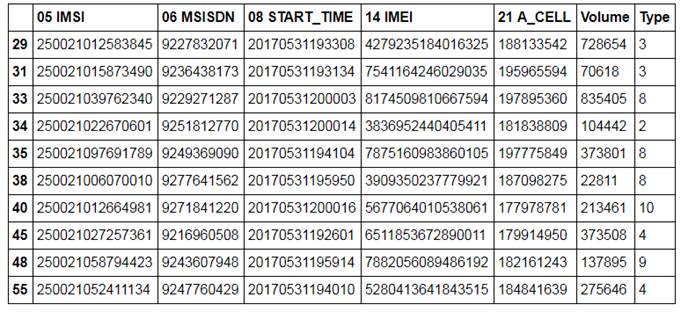
Какие алгоритмы машинного обучения можно применить к этим данным? Можно, например агрегировать потребление трафика разного типа по абонентам за определенный период и провести кластеризацию. Должна получиться какая-то такая картинка:
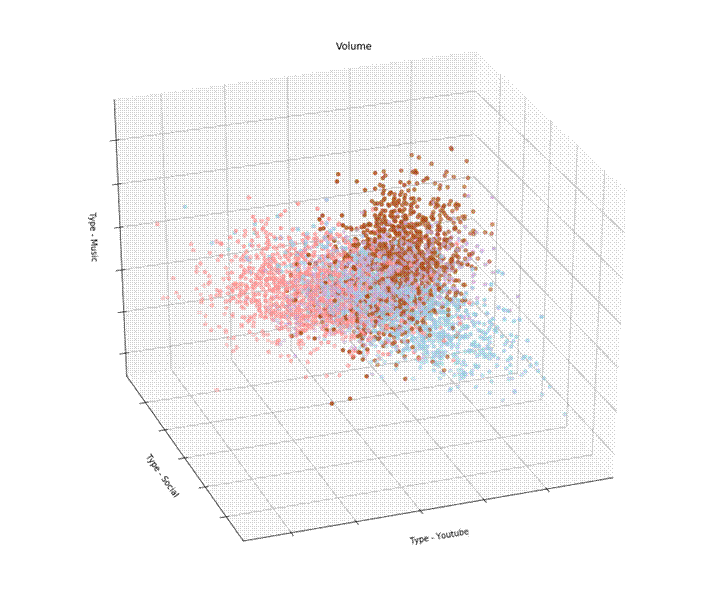
Т.е. если, например, результат кластеризации показал, что абоненты разделились на группы, которые по разному используют Youtube, соцсети и слушают музыку, то можно сделать тарифы, которые учитывают их интересы. Наверное, МегаФон так и поступил, выпустив линейку тарифов "Включайся!".
Что еще можно проанализировать в имеющихся данных? Есть несколько кейсов с оборудованием абонентов. Оператор знает модель устройства абонента и может, например, предлагать определенные услуги только пользователям Samsung. Или например, зная координаты базовых станций, можно нарисовать тепловую карту распределения телефонов Samsung (у меня нет реальных координат, поэтому карта к действительности не имеет отношения): https://alexeysushkov.carto.com/builder/573a4146-d194-41aa-8cbd-a155fe5e328e/embed
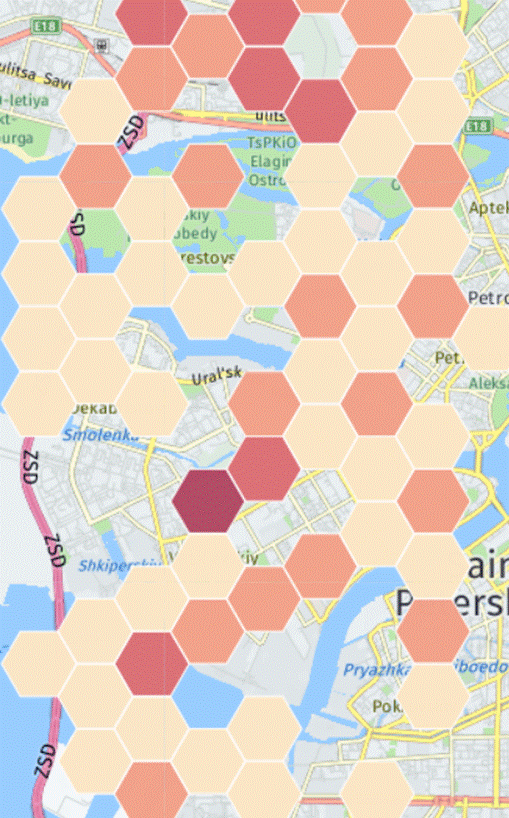
Может так получиться, что в каком-то регионе их окажется в процентном отношении больше, чем в других. Тогда эту информацию можно предложить Samsung-у. Далее можно посмотреть, на Top моделей устройств, с которых абоненты заходят в интернет:
Модель %
Apple A1457 5.879415
Apple A1586 4.775463
Apple A1688 3.206953
Apple A1429 1.548529
Apple A1387 1.473600
Apple A1633 1.443629
Apple A1530 1.418652
Simcom SIM900R 1.328738
Apple A1533 1.298766
Samsung SM-A310F/DS 1.103951
Apple A1723 1.098956
Samsung SM-A300F/DS 1.053999
Samsung SM-A510F/DS 0.974075
Apple A1332 0.949098
Apple A1524 0.939108
Samsung SM-J120F/DS 0.919127
Meizu Y685Q 0.884160
Samsung SM-A500F/DS 0.859184
Meizu Y685H 0.839203
Micromax Q415 0.709326
Xiaomi 2015112 0.709326
и сделать вывод, что большинство устройств - это Apple, модемы и Самсунги, в конце появляются Meizu, Micromax и Xiaomi.
Собственно это все применения, которые я смог найти. Конечно, по этим данным можно смотреть на разнообразные статистики и временные ряды, анализировать выбросы т.п., но вот так чтобы выявить какую-нибудь зависимость средствами машинного обучения... к сожалению я не вижу что можно еще сделать. Таким образом, общий вывод такой: для полноценного решения задач оператора связи нужны данные из всех имеющиеся информационных систем, поэтому только сам оператор может их решать эффективно.
Выводы
· В анализе данных никакой магии нет. Все основано на нескольких простых алгоритмов, понять и применять которые можно на интуитивном уровне.
· Конечно, остаются сложные задачи, решить которые можно только имея опыт и глубокие знания в статистики, в алгоритмах машинного обучения и программировании.
1.4 PS При чем тут облака? (необходимость раздела под вопросом)
Действительно, а при чем тут облака? Облака или виртуализация понадобятся на следующим уровне, когда мы будем строить промышленную систему, которая будет в реальном масштабе времени отслеживать активность абонентов, классифицировать их и предлагать им персонализированные предложения. Например такую систему: Customer Adviser https://www.billing.ru/products/customer/customer-adviser